In today’s e-commerce landscape, customer reviews hold immense power. But with thousands of reviews pouring in daily, manually analyzing them is like trying to count stars in the sky — impossible and overwhelming.
That’s where machine learning comes to the rescue! Businesses can find hidden gems within customer reviews, gain valuable insights, and make data-driven decisions to improve their products and services.
At the same time, they can also allow the customers to make informed and data-driven purchase decisions improving the customer experience and satisfaction.
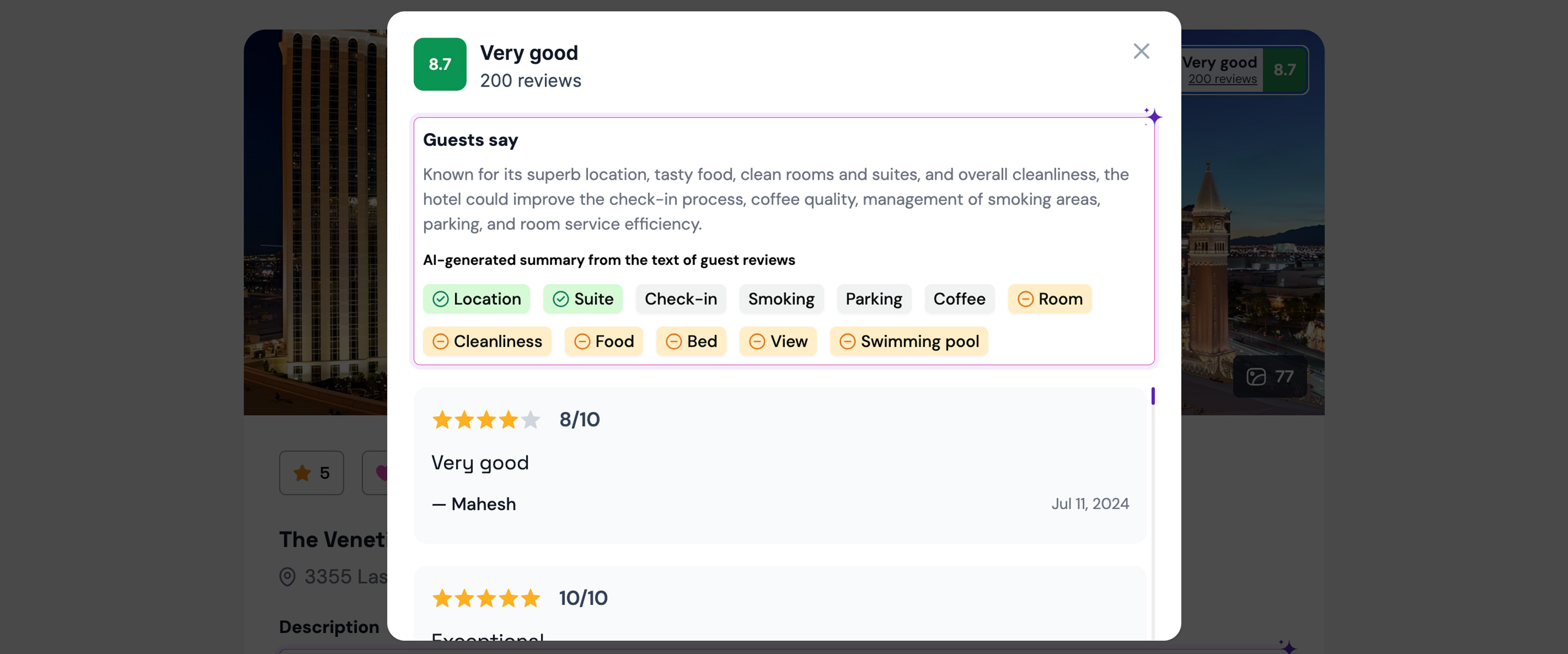
Review Summary of the iPhone from My Amazon Account
The Anatomy of a Review Analytics System
Amazon, the e-commerce giant, has a superb review analytics system. It seamlessly analyzes customer feedback, extracts key sentiments, and presents actionable insights to sellers and customers alike.
We took inspiration from it and decided to build our own review analysis system and unlock greater value for our customers.
But how does it work? Let’s break it down into its essential components:
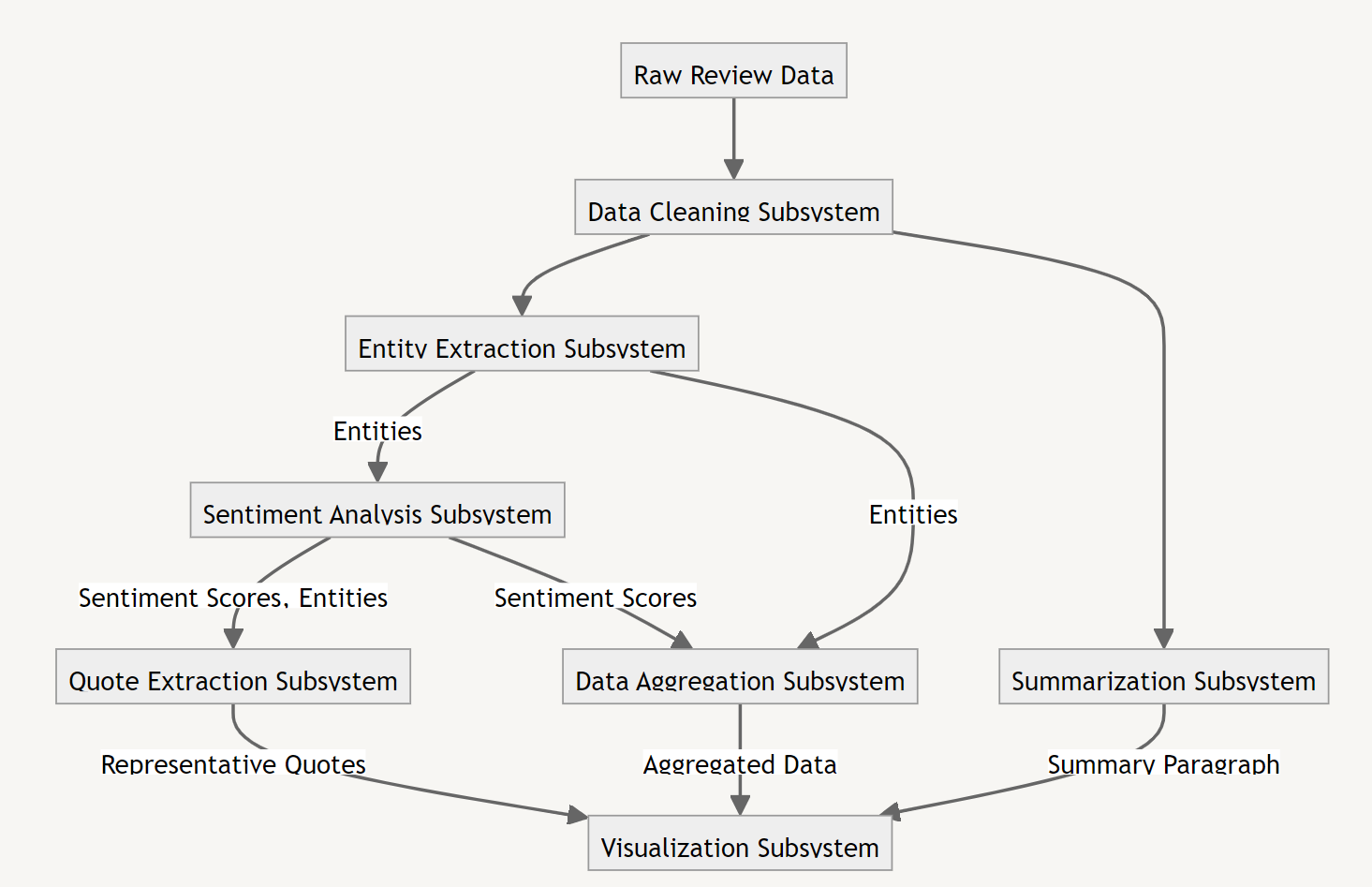
Breakdown by author
Next, I will share some techniques to implement each step. I will also guide you on how to approach a POC (Proof of Concept), as well as a production release.
A POC is a quick and easy prototype and can be generated by relying mostly on LLMs. Production is where you need to optimize for cost and accuracy, and the design choices will be based on your unique situation.
1. Data Cleaning: Preparing the Review Data
The first step in building a review analytics system is to clean and preprocess the raw review data. This involves tasks like:
Text normalization: Converting all text to lowercase and removing special characters and numbers.
Noise reduction: Eliminating irrelevant or non-standard language using regex patterns.
Spell correction: Implementing context-aware algorithms to fix spelling mistakes.
Python libraries like NLTK, TextBlob, and SpaCy are powerful tools for handling these preprocessing tasks efficiently. Here’s a code snippet demonstrating basic text cleaning:

For a POC you can do a basic text cleaning like the one above, or just prompt an LLM to clean the data for you.
For production, you would need to do more complex text cleaning and preprocessing involving lemmatization, spell correction, and stopwords removal. For some of our use cases, we even had to do attention-based word importance scoring.
2. Entity Extraction: Identifying Key Product Attributes
Once the review data is squeaky clean, it’s time to identify the key product attributes mentioned by customers. This is where entity extraction comes into play. Techniques like:
Domain expert input: Leveraging the knowledge of domain experts to generate a list of relevant entities.
Named Entity Recognition (NER): Training NLP models on domain-specific data to recognize product features.
Topic Modeling and Part-of-Speech Tagging: Employing statistical methods to uncover hidden themes and attributes.
By using models like BERT, spaCy, or custom LSTM networks, you can accurately extract entities from reviews and gain a deeper understanding of what customers are talking about.

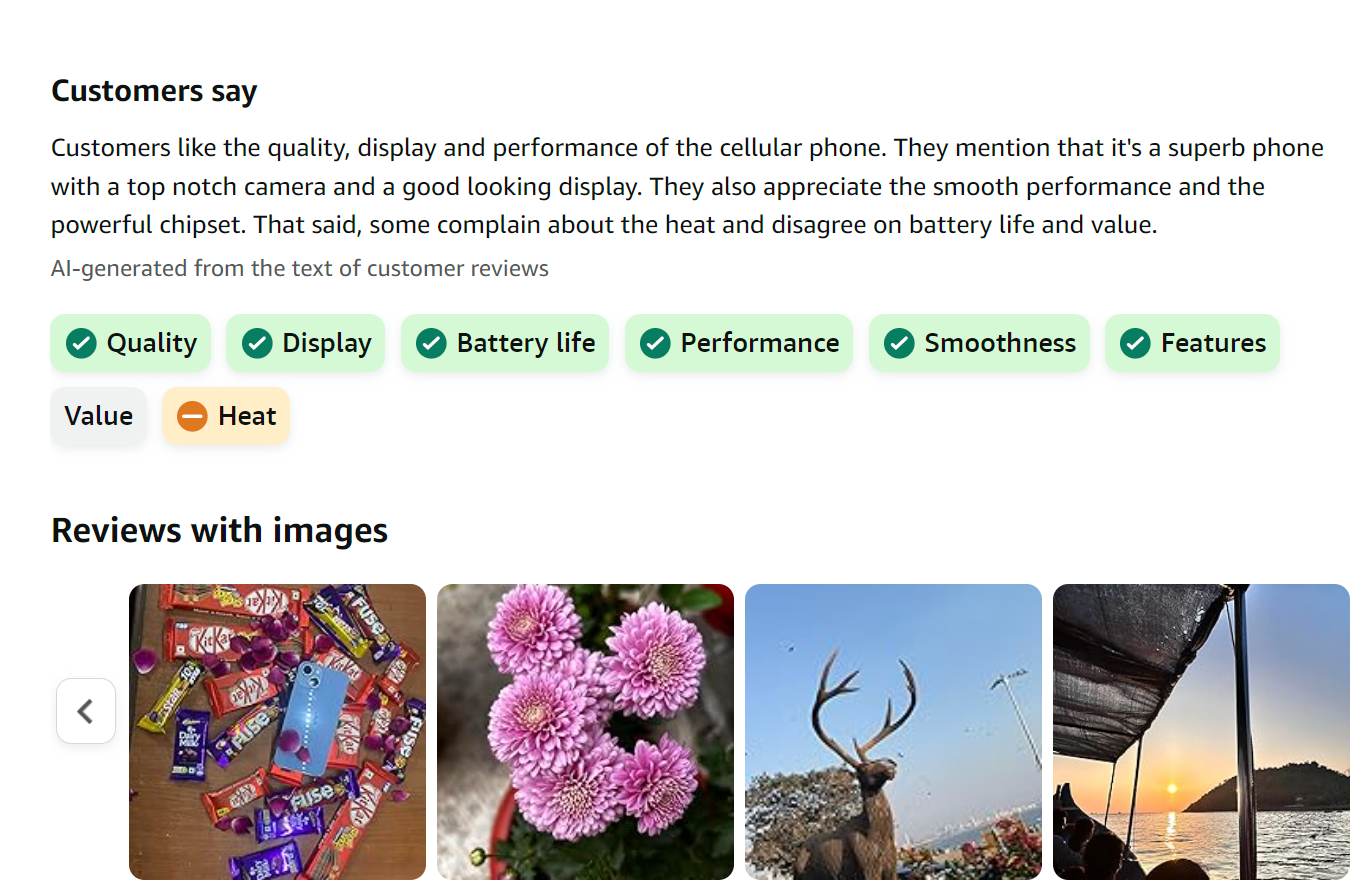
Wordcloud by author
For a POC, it makes sense to get a domain expert to do it for you or substitute domain experts with a top-of-the-line LLM like GPT-4 or Claude-Opus.
For a production setting, you would need to first identify if the entities are the same per document or different. For example, the entities when buying a clothing item would be different than when buying a book or a laptop.
In that case, asking a domain expert might not be feasible, and you would need to cluster the documents first into different categories. For each cluster, you can extract entities. The entity extraction can be as simple as word frequency analysis or as complex as transformer-based NER, depending on your use case.
3. Sentiment Analysis: Understanding Customer Emotions
Next, we need to determine the sentiment associated with each extracted entity. Sentiment analysis helps us understand whether customers feel positive, negative, or neutral toward specific aspects of a product. Some popular techniques include:
Basic Classifier: Training a basic classifier on top of Word2Vec embeddings to classify sentiments.
Sentiment libraries: Using pre-built libraries like VADER, TextBlob, or AFINN for quick and easy sentiment scoring.
Transformer models: Fine-tuning advanced models like BERT or RoBERTa for more nuanced sentiment detection.
By combining sentiment analysis with dependency parsing, you can attribute sentiments to specific entities and gain granular insights into customer opinions.

Sentiments generated by author using LLMs
For a POC, you can do a basic sentiment analysis using the libraries above. But with the advent of LLMs, it is far easier and more accurate to have the LLMs generate the sentiment and attribute it to the entities in one go.
For production settings, in the case of a high volume of reviews, using an off-the-shelf LLM might become prohibitively expensive. Instead, you can use LLMs to generate training data and then fine-tune an SLM (Small Language Model) like LLAMA, T5, or even BERT to great effect.
4. Data Aggregation: Combining Sentiments and Entities
Now that we have extracted entities and determined their associated sentiments, it’s time to aggregate the data. This involves:
Counting occurrences: Tallying the number of positive, negative, and neutral mentions for each entity.
Weighted sentiment scoring: Assigning higher weights to more influential or helpful reviews.
The output of this subsystem provides a holistic view of customer sentiment towards different aspects of a product.

Author’s POC
For a POC, you can perform basic data aggregation by counting the number of positive, negative, and neutral reviews for each entity. For presentation, you can use a threshold-based logic or simply select the top-k entities in each class.
For production, you would need to do more sophisticated data aggregation by weighing each sentiment based on the strength of the wording, recency factor, popularity of the review, and other factors. Then combine them to get a final weighted sentiment score for each entity.
5. Quote Extraction: Showcasing Customer Voices
To add credibility and authenticity to the insights, it’s crucial to highlight representative customer quotes. Techniques like:
Lucene-based keyword search: Finding relevant quotes based on entity and sentiment keywords.
Vector DB-based search: Using vector representations to identify semantically similar quotes.
By selecting impactful and diverse quotes, you can bring customer voices to the forefront and support the sentiment analysis findings.
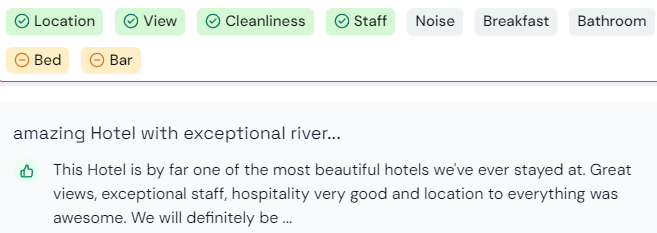
Author’s POC
For a POC, you can use search libraries like Lucene. They are easy to use and work well for small to medium-sized datasets.
For production, you might need to do quote extraction based on semantic search or hybrid search.
6. Summarization: Generating Concise Insights
Summarizing the overall sentiment across multiple reviews is essential for providing concise and digestible insights. Methods like:
Rule-based summaries: Generating summaries based on predefined rules and templates.
GenAI summarization: Leveraging advanced models like BERT or LLAMA to create coherent summaries.
These summaries serve as quick snapshots of customer opinions, making it easier for stakeholders to grasp the key takeaways.

Amazon Review Summary
For a POC, you can do a basic summarization by listing the top 10 entities with the most positive, negative, and neutral reviews in a sentence. This is how Amazon does it too.
For production, you would need to do more complex summarization by fine-tuning a BERT model or LLAMA.
7. Visualization: Bringing Insights to Life
The final piece of the puzzle is presenting the analyzed data in a visually compelling and interactive way. Techniques like:
Charts and color-coded sentiment scores: Using intuitive visualizations to convey sentiment distribution.
Interactive dashboards: Enabling users to drill down into specific entities, quotes, and sentiment trends.
Real-time sentiment tracking: Monitoring live feedback and updating visualizations in real-time.
JavaScript libraries like D3.js and Chart.js, along with web frameworks like React or Angular, provide the tools to create engaging and dynamic visualizations.
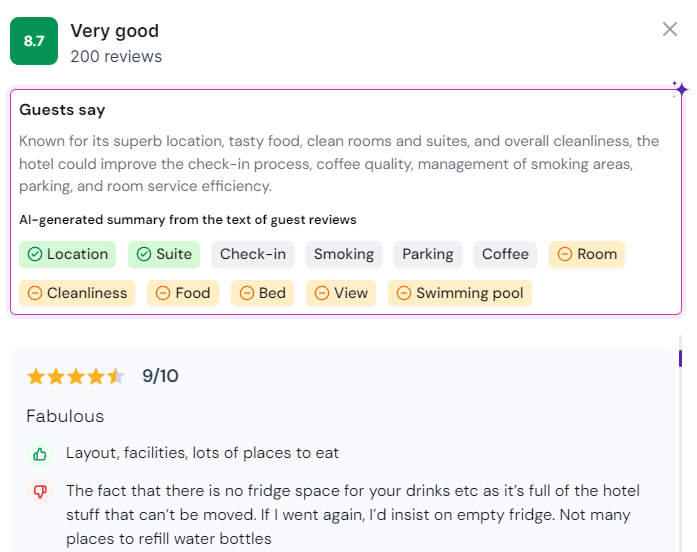
Final visualization
Real-World Impact and Best Practices
Implementing an AI-powered review analytics system can have a big impact on businesses. Case studies have shown that companies that leverage review analytics have experienced:
Increased customer satisfaction: By identifying and addressing pain points highlighted in reviews.
Product innovation: Using customer feedback to guide product development and improvements.
To ensure the success of your review analytics system, consider the following best practices:
Continuously update and refine your models to adapt to changing customer language and preferences.
Ensure data privacy and security by anonymizing customer information and implementing strict access controls.
Challenges and Limitations
While AI-powered review analytics offers immense benefits, it’s essential to be aware of potential challenges and limitations:
Data privacy concerns: Handling customer data requires strict adherence to privacy regulations and ethical practices.
Need for large volumes of review data: To train accurate models, a substantial amount of diverse review data is necessary.
Limitations of automated sentiment analysis: Sarcasm, irony, and complex emotions can sometimes be misinterpreted by automated systems.
Addressing these challenges requires a combination of technical solutions, such as data anonymization and model fine-tuning, as well as organizational measures, like establishing clear data governance policies and involving human experts in the loop.